Scratching an itch
A fuzzy finder is invaluable - Triggering the fuzzy finder with denite
(plugin that shows filterable lists from many sources - files, buffers, tags etc) is probably the most frequent operation
in vim/neovim. Having something that’s used so frequently fast and correct is critical!
Given that I have to use windows (still on 8.1) - so tools like fzy or fzf
don’t exactly work properly.
As I said, I use denite to switch/jump buffers, tags, files, whatever. I’ve been using nixprime/cpsm as my matcher/filter
- but it’s been a pain to get it working on windows - requires VC++, Boost and needs mucking around with cmake scripts.
After a recent update broke compilation, I got pissed enough to attempt to write my own fuzzy finder that would be:
-
work cross platform
-
great relevance matching
-
easy to hack on
And so, fruzzy was born
Getting started
So the path of least resistance is to just write a matcher/filter plugin for denite in python. This is exactly what I did. Matching’s the objective part - each character of the query should be present in the target string in the same order. Where things get interesting is the ranking of matches - you can use various elements - where was the match, how closely are they clustered etc to arrive at a score and then rank the matches according to highest score. This is of course, entirely subjective and different people will have different expectations.
Based on my own usage, I came up with a few (and tweaked them over a couple of days):
-
How closely clustered are the matches
-
How close to the end is the match - closer to the end is preferred.
-
Are there any separators before/after the match positions?
-
Are matches camelCased? (ie prev char is lowercase and matched char is uppercase)
-
How much of the match is in the last portion of the path?
Optimizing the matching algorithm was an interesting exercise - but all in all involved walking the string from the end so that we find matches near the end first, calculating the score of each search and then picking out the top N based on the score. Tweaking the ranking involved few subjective tests of various queries over my last 100 visited files as the test data and then playing with the signals and weights till I was happy with the results.
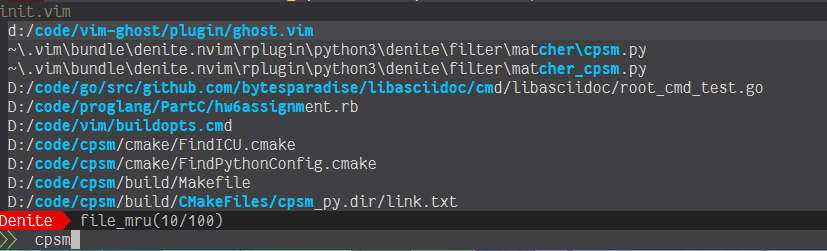
Here are a few screenshots comparing it with CPSM, fzf and fzy:
CPSM isn’t even good

Errata [2018-09-29]: I fatfingered the query above and some of you were quick to point that out. Fixed below


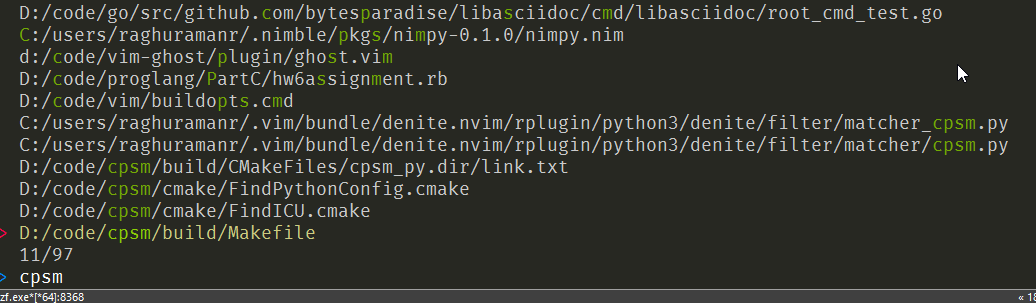
FZF and FZY are much better
(and do a better job of highlighting matched range)
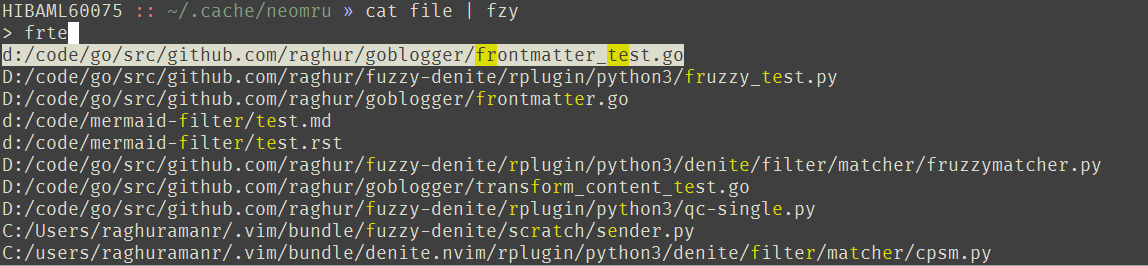
How does Fruzzy do?



Performance
I wrote a quick few benchmarks with pytest-benchmark using the same fixed array of 100 filenames. Running pytest and then
tweaking the match or scoring algorithm till the numbers improved was a fun game of micro benchmarking. The python
version came in at a median time of 300μs - 625μs (very respectable IMO)

Can we go faster?
First attempt - Shall we Go?

So I liked cpsm because it was fast - I mean, really fast and that was because it was compiled down to a native module. I wanted to do the same - minus the pain of dealing with C++ and Boost. I first tried my hand with Go but that didn’t work very well - involved generating a shared library from Go and then doing the C bindings based on the generated header file. The Go-Python interface is iffy and while I managed to get it working enough to send in an array of strings, it was slow. I learnt the ropes from this Medium post but eventually gave up
Let’s Nim

I’d heard about Nim and have been meaning to give it a try. It’s a statically typed, compile to native systems programming langugage with syntax that feels a lot like python. For python interop, Google showed up nimpy - an amazing project that makes it super easy to call nim from python.
Nim’s very easy to get started with and after perusing the tutorial, I had a working comms between Nim and python without much effort. Given the amount of trouble I had in Go, this was super encouraging. A couple of hours later, I had a working port of my python code (which was super easy given that it was almost the same). However, after compiling, I ran into weird problems - and this is where nimpy’s owner came to the rescue - He is extremely quick to respond and fix issues and in general answer questions on github. Using the latest development compiler fixed up all the issues. Performance though, was another thing. I came in at about 600 - 900μs for the same benchmarks. Not much of an improvement if you’re going twice slower, is it?
And then the penny dropped! - After a facepalm moment, I turned on release build and that improved timings to 100 - 200us. At this point, I started optimizing in earnest
-
Dropped all generics and stuck to basic types.
-
Minimize amount of data passed between nim/python - I can’t avoid passing in a list of strings but instead of returning string, the nim code just returns indices.
-
Minimize heap allocations and copying
After a day or so of lots of iterations and tweaks, I finally ended up with median times of 40-60μs! That’s close to 7 - 10x improvement on pure python. Well worth the trouble of installing a native module IMO. Also, the baseline cost of invoking Nim from python with an array of strings comes in at about 15μs - so we’re just 2x - 3x from there.

I wrote the denite plugin such that it defaults to the python implementation. Users can install the native module and the denite plugin will use it if available. If there’s a problem loading the native module, then it’ll fall back to using the pure python implementation
Parting thoughts
Nim’s a beautiful language - I mean I actually like Nim a LOT and managed to build something that’s worth showing around in a couple of days. It’s just not as famous as the other 'new' languages. It’s pleasant to write in and I actually enjoy it - I can’t say that about Golang - writing Go just feels like an exercise in drudgery.
With fruzzy, I’ve noticed over the last couple of days that I don’t stop to check what’s showing on the top of the heap… I just type a few chars and switch and only once in a while I’m surprised that I didn’t land on the file I intended.
Head over to the repo to install Fruzzy
